State Feedback Controller With Feed Forward Gain
Full state feedback (FSF), or pole placement, is a method employed in feedback control system theory to place the closed-loop poles of a plant in pre-determined locations in the s-plane.[1] Placing poles is desirable because the location of the poles corresponds directly to the eigenvalues of the system, which control the characteristics of the response of the system. The system must be considered controllable in order to implement this method.
Principle [edit]
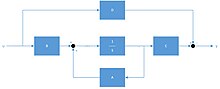
If the closed-loop dynamics can be represented by the state space equation (see State space (controls))

with output equation

then the poles of the system transfer function are the roots of the characteristic equation given by

Full state feedback is utilized by commanding the input vector . Consider an input proportional (in the matrix sense) to the state vector,


System with state feedback (closed-loop)
- .

Substituting into the state space equations above, we have


The poles of the FSF system are given by the characteristic equation of the matrix , . Comparing the terms of this equation with those of the desired characteristic equation yields the values of the feedback matrix which force the closed-loop eigenvalues to the pole locations specified by the desired characteristic equation.[2]

![{\displaystyle \det \left[s{\textbf {I}}-\left({\textbf {A}}-{\textbf {B}}{\textbf {K}}\right)\right]=0}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3a787ae48cf0cd103b8c8dfe6d8994bd370b71db)

Example of FSF [edit]
Consider a system given by the following state space equations:

The uncontrolled system has open-loop poles at and . These poles are the eigenvalues of the matrix and they are the roots of . Suppose, for considerations of the response, we wish the controlled system eigenvalues to be located at and , which are not the poles we currently have. The desired characteristic equation is then , from .







Following the procedure given above, the FSF controlled system characteristic equation is

where

Upon setting this characteristic equation equal to the desired characteristic equation, we find
- .

Therefore, setting forces the closed-loop poles to the desired locations, affecting the response as desired.
This only works for Single-Input systems. Multiple input systems will have a matrix that is not unique. Choosing, therefore, the best values is not trivial. A linear-quadratic regulator might be used for such applications[ citation needed ].
See also [edit]
- Pole splitting
- Step response
- Ackermann's Formula
- Linear-quadratic regulator
References [edit]
- ^ *Sontag, Eduardo (1998). Mathematical Control Theory: Deterministic Finite Dimensional Systems. Second Edition. Springer. ISBN0-387-98489-5.
- ^ Control Design Using Pole Placement
External links [edit]
- Mathematica function to compute the state feedback gains
Source: https://en.wikipedia.org/wiki/Full_state_feedback
0 Response to "State Feedback Controller With Feed Forward Gain"
Post a Comment